

Problem
Many Sitecore developers faced the problem when Sorl search, for example, hits some results for query term "currency" and hits no results for query "currencies". And it is very simple example, what about search terms like "independence" vs. "dependency". What about "hard" languages like German or Russian where related word have long distance metric?
Stemming
Stemming is the process of reducing inflected (or sometimes derived) words to their word stem, base or root form - generally a written word form. The stem need not be identical to the morphological root of the word; it is usually sufficient that related words map to the same stem, even if this stem is not in itself a valid root.
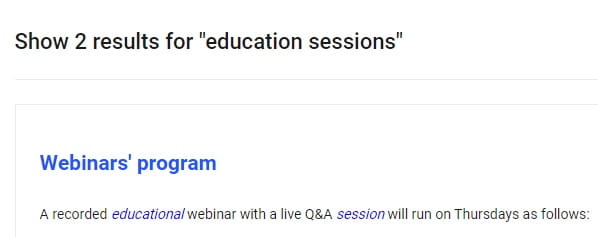
Sorl has out-of-the-box solutions for words stemming, but why it doesn`t work out-of-the-box in Sitecore and how to make it works?
First of all, lets find out why it doesn`t work. Let`s say we execute a search query for text field content_t. Navigate to Solr admin pane, Schema tab, and select your field to see detailed information:
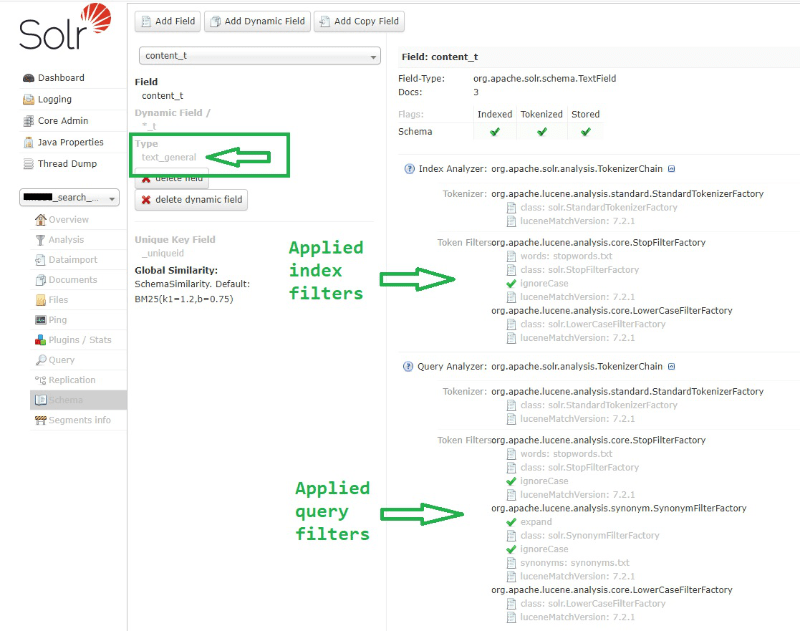
As you can see, field is mapped to "text_general" type, and also there are NO ANY stemminq filters for index and query analyzers. Also you can see that there are language versions of your dynamic field that are mapped to corresponding language types, like "text_en", "text_de" etc.:
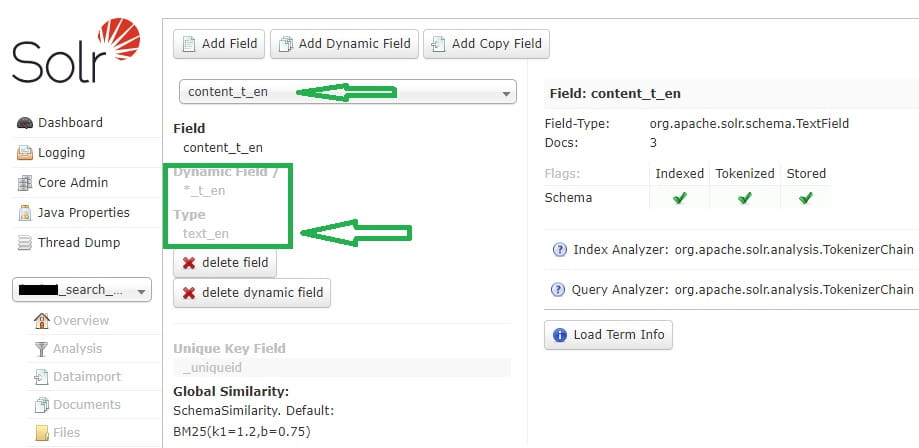
Let`s navigate to managed schema of our index to see what filters are applied to these field types:
<fieldtype name="text_en" class="solr.TextField" positionincrementgap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"></tokenizer>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignorecase="true"></filter>
<filter class="solr.LowerCaseFilterFactory"></filter>
<filter class="solr.EnglishPossessiveFilterFactory"></filter>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"></filter>
<filter class="solr.PorterStemFilterFactory"></filter>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"></tokenizer>
<filter class="solr.SynonymGraphFilterFactory" expand="true" ignorecase="true" synonyms="synonyms.txt"></filter>
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignorecase="true"></filter>
<filter class="solr.LowerCaseFilterFactory"></filter>
<filter class="solr.EnglishPossessiveFilterFactory"></filter>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"></filter>
<filter class="solr.PorterStemFilterFactory"></filter>
</analyzer>
</fieldtype>
...
<fieldtype name="text_de" class="solr.TextField" positionincrementgap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"></tokenizer>
<filter class="solr.LowerCaseFilterFactory"></filter>
<filter class="solr.StopFilterFactory" format="snowball" words="lang/stopwords_de.txt" ignorecase="true"></filter>
<filter class="solr.GermanNormalizationFilterFactory"></filter>
<filter class="solr.GermanLightStemFilterFactory"></filter>
</analyzer>
</fieldtype>
As you can see each language version of field has its own stemmer in filters. But why stemming doesn`t work? First of all, "text_en" dynamic field is mapped to "text_general" type, but text_general type doesn`t have any stemmers in analyzer filters by default:
<dynamicField name="*_t_en" type="text_general" indexed="true" stored="true"/>
...
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="false">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.SynonymFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Solutions
There are two ways to solve this problem and it depends on how your Solr search is implemented:
-
Your search is Language specific. It means that your search uses CultureExecutionContext and query hits to exact language version of field:
var results = context.GetQueryable( new CultureExecutionContext(Context.Language.CultureInfo)) .Where(predicat); or var result = context.GetQueryable () .InContext(new CultureExecutionContext(Context.Language.CultureInfo)) .Where(predicat); In this way search query hits exact language version of field, like content_t_de, not content_t.
In this case, all that you need is to change "*_t_en" mapping to "text_en" in managed schema and stemming starts to work:
<dynamicField name="*_t_en" type="text_en" indexed="true" stored="true"/> -
If it is not possible for you to use Language specific search, you can map "text" field to "text_en" type instead of default "text_general" in managed schema:
<field name="text" type="text_en" multiValued="true" indexed="true" stored="false"/>Or you can add PorterStemFilterFactory filter to text_general type in managed schema (at least to query analyzer):
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="false"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.PorterStemFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/> <filter class="solr.SynonymFilterFactory" expand="true" ignoreCase="true" synonyms="synonyms.txt"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.PorterStemFilterFactory"/> </analyzer> </fieldType>In this second case stemming works only for english content, because if you don`t have Language specific search, you query will always hit content_t and only one english PorterStemFilterFactory filter will applied.
Note: be sure to restart Solr after schema changes and rebuild corresponging index.
Tip: Solr admin has Analysis tab where you can test configurations of your field types and see in real time how tokenizers and filters are applied to your queries at index and query time:
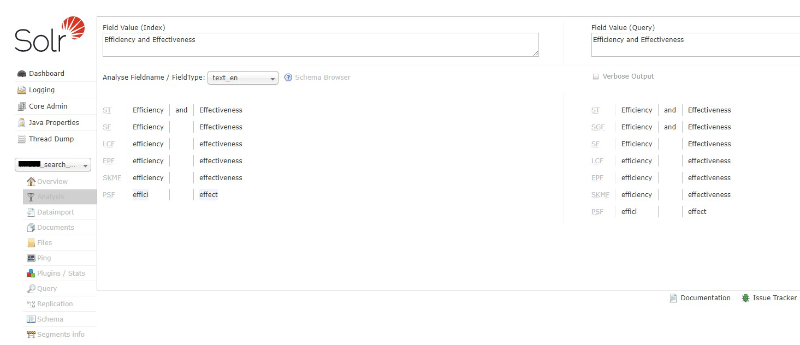
As you can see, Solr has powerful filters and analysers and you get more accurate language specific results only by small changes in configurations or your Sitecore queries. Good luck!
