

Before we start, let's take a little look at the algorithms/mechanisms of ML in general.
ML algorithms can be divided into the following groups:
- Supervised learning - indicates the presence of the supervisor as a teacher. It is learning in which we teach or train the machine using data which is well labeled that means some data is already tagged with the correct answer. After that, the machine is provided with a new set of examples(data) so that supervised learning algorithm analyses the training data(set of training examples) and produces a correct outcome from labeled data.
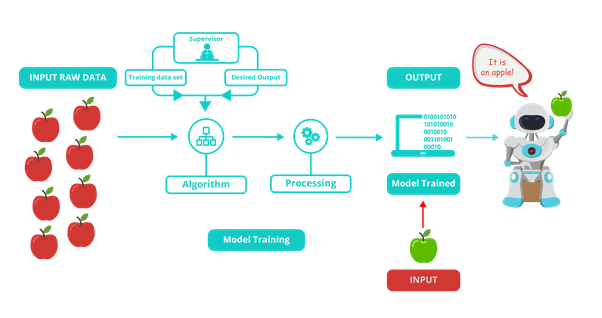
Supervised learning classified into two categories of algorithms:
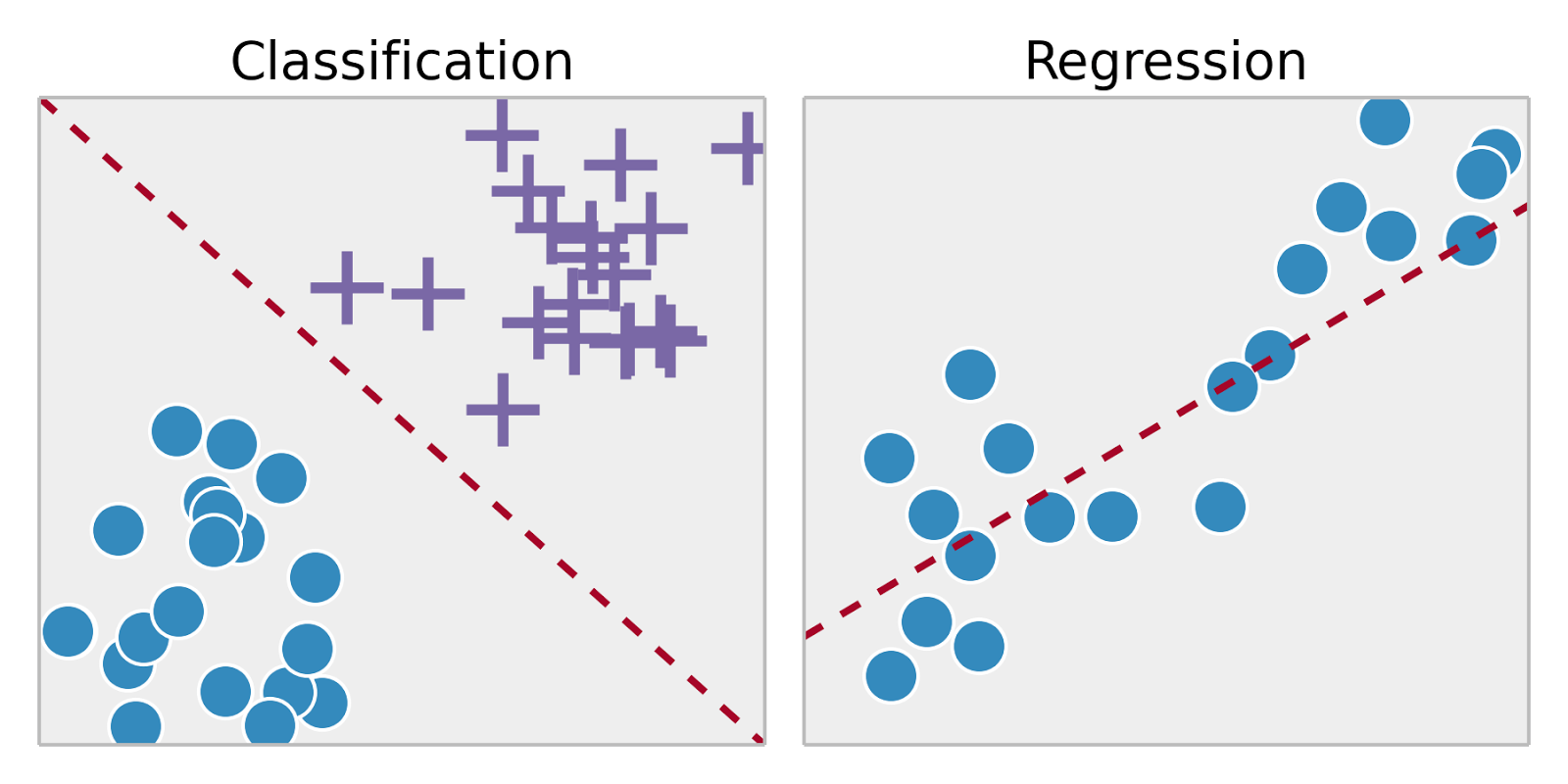
- Сlassification. A classification problem is when the output variable is a category, such as “Red” or “Blue” or “disease” and “no disease”.
- Regression. A regression problem is when the output variable is a real value, such as “dollars” or “weight”.
- Unsupervised learning - the training of machine using information that is neither classified nor labeled and allowing the algorithm to act on that information without guidance. Here the task of the machine is to group unsorted information according to similarities, patterns, and differences without any prior training of data. The machine has no idea about the “groups qualities” but it can categorize them according to their similarities, patterns, and differences.
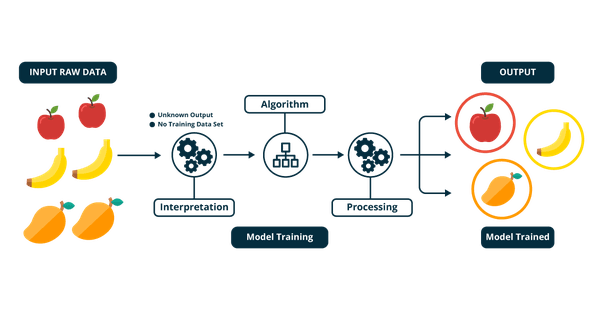
Unsupervised learning classified into two categories of algorithms:
- Clustering. A clustering problem is where you want to discover the inherent groupings in the data, such as grouping customers by purchasing behavior.
- Association. An association rule learning problem is where you want to discover rules that describe large portions of your data, such as people that buy X also tend to buy Y.
- Semi-Supervised Machine Learning. Combination of supervised and unsupervised ML. Problems where you have a large amount of input data (X) and only some of the data is labeled (Y) are called semi-supervised learning problems. These problems sit in between both supervised and unsupervised learning. A good example is a photo archive where only some of the images are labeled, (e.g. dog, cat, person) and the majority are unlabeled.
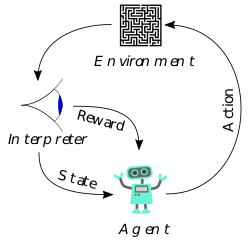
- Reinforcement learning. Artificial intelligence (learn from mistakes). Unlike cases where the input is formally fed to an algorithm, in reinforcement learning the algorithm receives input based upon experience.
Unsupervised and supervised algorithms can be easily and widely used with Cortex. So, problem for our scenario is called Clustering. By applying ML clustering techniques, we will identify similar customers and group them in clusters without having pre-existing categories. Clustering is a good way to identify groups of 'related or similar things' without having any pre-existing category list. (That is precisely the main difference between clustering and classification). For our scenario, we will use the purchasing behavior of customers (RFM values) as clustering data.
Next step is to choose the ML engine. There are a lot of Machine Learning engines that we can use for our solutions. Microsoft provides these:
- Microsoft Machine Learning Server
- Azure Machine Learning service
- SQL Server Machine Learning services with R
- ML.Net cross-platform machine learning framework
OOUT Sitecore Processing Engine is built to work with Microsoft Machine Learning Server. To setup connection to ML server you need to configure ProcessingEngine\App_Config\ConnectionStrings.config file (comments in file ProcessingEngine\App_Data\Config\Sitecore\Processing\sc.Processing.Engine.Scripting.Mrs.xml can be useful). Then you need to inject IScriptSessionFactory in your code, create MrsScriptSession and execute your R script. It looks something like:
public class MrsModel: IModel<Interaction>
{
private readonly IScriptSessionFactory _scriptSessionFactory;
public MrsModel(IReadOnlyDictionary<string, string> options, IScriptSessionFactory scriptSessionFactory)
{
_scriptSessionFactory = scriptSessionFactory;
}
public async Task<IReadOnlyList<object>> EvaluateAsync(string schemaName, CancellationToken cancellationToken, params TableDefinition[] tables)
{
var rScript = "[your R script:] x <- 1.0 …";
var sessionFactory = await _scriptSessionFactory.CreateSessionAsync(cancellationToken);
await sessionFactory.InitializeContextAsync(_key, cancellationToken);
JToken result = await sessionFactory.ExecuteScriptAsync(rScript, cancellationToken);
// do something
}
...
}See “Sitecore.Processing.Engine.Scripting.Mrs.dll” source code for better understanding of internal processes.
For our scenario, we will use ML.Net framework as an ML engine. The main reason - is that we can use C# to code our ML algorithms and business logic. It also has a lot of examples, well documented and easy to install. We will implement our ML engine as a separate. Net Core application that will communicate with Cortex by using WebAPI requests. (For demo purposes you can install it directly in Processing Engine from Nuget).
Clustering task can be divided into 4 logical steps:
- Build Model (data pre-processing). We will skip this because we already have projected data in Cortex.
- Train Model. We will train the customer segmentation model by fitting or using the training data with the selected algorithm.
- Evaluate Model. We will evaluate the accuracy of the model. This accuracy is measured using the ML.Net ClusteringEvaluator, and some specific metrics are returned as a result of the evaluation. We can use these metrics to determine how good or bad is our model.
- Predict (Consume) Model. We load the model created during the last step and execute the model on the data (contact or batch of contacts). As a result, we will have a predicted cluster for our contacts (or batch of contacts).
First of all, we need to install ”Microsoft.ML” packages from NuGet.
Next, we implement CustomersSegmentator class encapsulating all business logic of our steps:
public class CustomersSegmentator
{
private static MLContext _mlContext;
// train model will be saved in file system after caclulation
private static string TrainedModelFile => Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "data.model");
private IDataView _testingDataView;
private static ITransformer _transformer;
private static ITransformer TrainModel
{
get
{
if (_transformer != null) return _transformer;
return LoadModel();
}
set
{
_transformer = value;
SaveModel(_transformer);
}
}
public ClusteringMetrics Train(List<Rfm> list)
{
_mlContext = new MLContext(42);
var dataView = _mlContext.Data.LoadFromEnumerable(list);
//Split dataset in two parts: TrainingDataset (80%) and TestDataset (20%)
var trainingDataView = _mlContext.Clustering.TrainTestSplit(dataView);
_testingDataView = trainingDataView.TestSet;
string featuresColumnName = "Features";
// for the demo we will split contacts into 5 clusters (in this case we can easily define what
// cluster contains ‘best’ customer, what contains ‘worst’ and find similar (good and bad) customers with fair accuracy)
var pipeline = _mlContext.Transforms
.Concatenate(featuresColumnName, "R", "M", "F")
.Append(_mlContext.Clustering.Trainers.KMeans(featuresColumnName, clustersCount: 5));
var model = pipeline.Fit(trainingDataView.TrainSet);
var metrics = Evaluate(model);
TrainModel = model;
return metrics;
}
public ClusteringMetrics Evaluate(ITransformer model)
{
Console.WriteLine("Evaluating Model with Test data");
var predictions = model.Transform(_testingDataView);
var metrics = _mlContext.Clustering.Evaluate(predictions, score: "Score", features: "Features");
// just for debugging purposes, we don`t use evaluation metrics for making decisions
Console.WriteLine();
Console.WriteLine("Model quality metrics evaluation");
Console.WriteLine("--------------------------------");
Console.WriteLine($"AvgMinScore: {metrics.AvgMinScore:P2}");
Console.WriteLine($"Dbi: {metrics.Dbi:P2}");
Console.WriteLine($"Nmi: {metrics.Nmi:P2}");
Console.WriteLine("End of model evaluation");
TrainModel = model;
return metrics;
}
public List<int> Predict(List<ClusteringData> records)
{
var list = new List<ClusteringPrediction>();
var predictionFunction = TrainModel.CreatePredictionEngine<ClusteringData, ClusteringPrediction>(_mlContext);
for each (var record in records)
{
list.Add(predictionFunction.Predict(record));
}
return list.Select(x => (int)x.SelectedClusterId).ToList();
}
private static ITransformer LoadModel()
{
ITransformer model;
using (var stream = new FileStream(TrainedModelFile, FileMode.Open, FileAccess.Read, FileShare.Read))
{
model = _mlContext.Model.Load(stream);
}
return model;
}
private static void SaveModel(ITransformer model)
{
using (var fileStream = new FileStream(TrainedModelFile, FileMode.Create, FileAccess.Write, FileShare.Write))
{
_mlContext.Model.Save(model, fileStream);
}
}
}And we also create WebAPI controller RfmController that will be used for communication with Cortex:
[Route("api/[controller]")]
[ApiController]
public class RfmController : ControllerBase
{
[HttpPost("train")]
public bool Train([FromBody] List<Rfm> data)
{
if (data != null && data.Any())
{
var segmentator = new CustomersSegmentator();
segmentator.Train(data);
return true;
}
return false;
}
[HttpPost("predict")]
public List<int> PredictList([FromBody] List<ClusteringData> data)
{
var segmentator = new CustomersSegmentator();
return segmentator.Predict(data);
}
}That`s all. Our Machine Learning engine is ready.
Next, we come back to our Processing Engine and configure our MLNetService.
First, we need to pass WebApi endpoints. To do it we just add them as optional parameters in service registration. File “sc.Processing.Services.MLNet.xml”:
<Settings>
<Sitecore>
<Processing>
<Services>
<IMLNetService>
<Type>Demo.Foundation.ProcessingEngine.Services.MLNetService, Demo.Foundation.ProcessingEngine</Type>
<As>Demo.Foundation.ProcessingEngine.Services.IMLNetService, Demo.Foundation.ProcessingEngine</As>
<LifeTime>Transient</LifeTime>
<Options>
<MLServerUrl>http://localhost:56399</MLServerUrl>
<TrainUrl>/api/rfm/train</TrainUrl>
<PredictUrl>/api/rfm/predict</PredictUrl>
</Options>
</IMLNetService>
</Services>
</Processing>
</Sitecore>
</Settings>We will also use RestSharp for API requests and serialization. Thus our service will look like this:
public class MLNetService : IMLNetService
{
private readonly string _trainUrl;
private readonly string _predictUrl;
private readonly string _mlServerUrl;
public MLNetService(IConfiguration configuration)
{
_mlServerUrl = configuration.GetValue<string>("MLServerUrl");
_trainUrl = configuration.GetValue<string>("TrainUrl");
_predictUrl = configuration.GetValue<string>("PredictUrl");
}
public ModelStatistics Train(IReadOnlyList<IDataRow> data)
{
...
var client = new RestClient(_mlServerUrl);
var request = new RestRequest(_trainUrl, Method.POST);
request.AddJsonBody(businessData);
var response = client.Execute<bool>(request);
var ok = response.Data;
if (!ok)
{
throw new Exception("something is wrong with ML engine, check it");
}
return new ModelStatistics();
}
public IReadOnlyList<PredictionResult> Evaluate(IReadOnlyList<IDataRow> data)
{
...
var client = new RestClient(_mlServerUrl);
var request = new RestRequest(_predictUrl, Method.POST);
request.AddJsonBody(businessData);
var response = client.Execute<List<int>>(request);
var prediction = response.Data;
return businessData.Select((t, i) => new PredictionResult {Email = t.GetContactEmail(), Cluster = predictions[i]}).ToList();
}
}
}
return results;
}
}
public interface IMLNetService
{
ModelStatistics Train(IReadOnlyList<IDataRow> data);
IReadOnlyList<PredictionResult> Evaluate(IReadOnlyList<IDataRow> data);
}Here are some links that will help you understand this topic better:
https://github.com/dotnet/machinelearning
https://github.com/dotnet/machinelearning-samples
https://github.com/Microsoft/ML-Server
https://github.com/dotnet/machinelearning-samples/tree/master/samples/csharp/getting-started/Clustering_CustomerSegmentation
http://www.kimberlycoffey.com/blog/2016/8/k-means-clustering-for-customer-segmentation
https://towardsdatascience.com/find-your-best-customers-with-customer-segmentation-in-python-61d602f9eee6
Table of contents Dive into Sitecore Cortex and Machine Learning - Introduction
Read next Part 6 - Implementation of Training and Evaluation workers.
Do you need help with your Sitecore project?

